LLM-as-Judge Evaluation
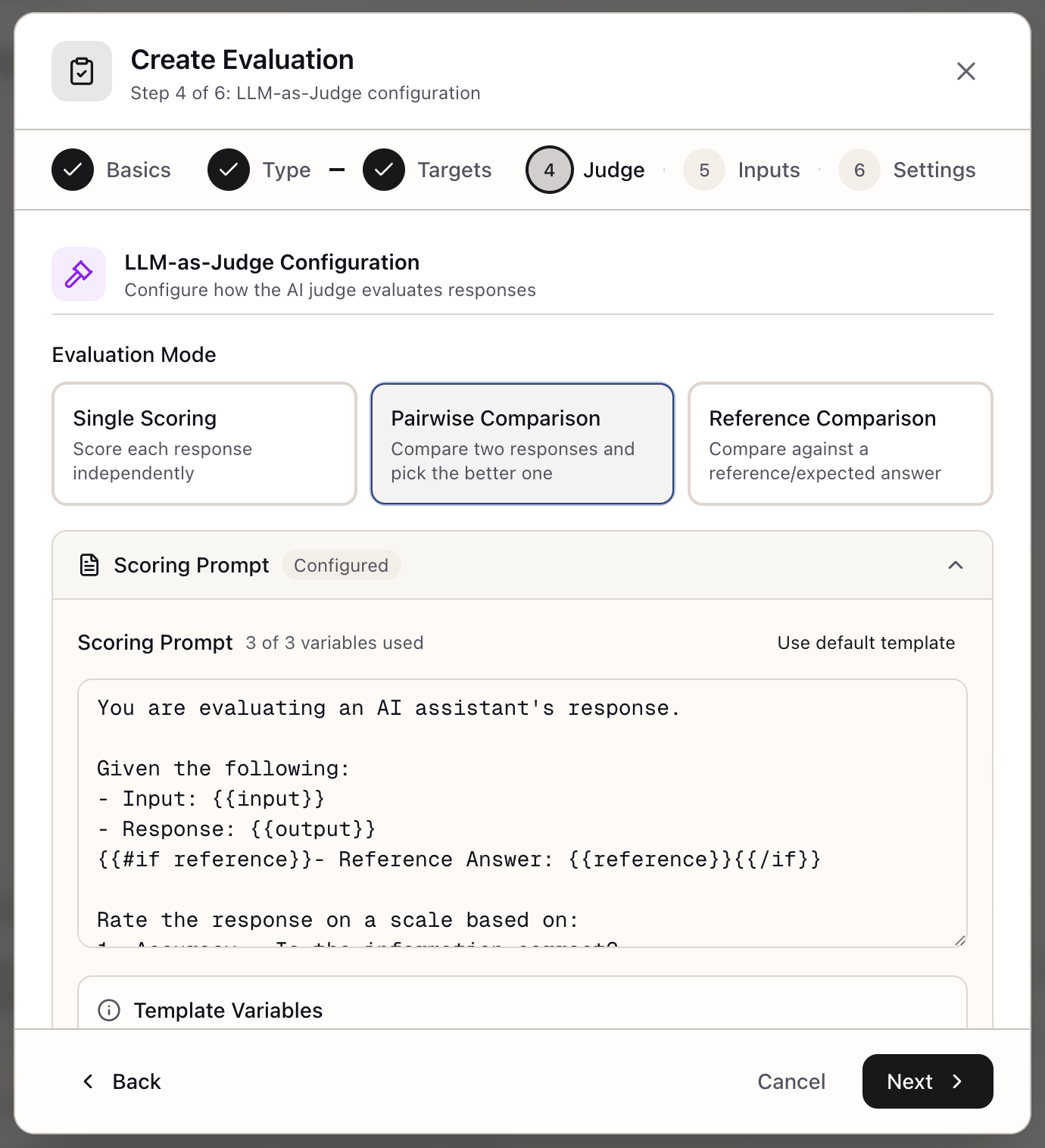
When I need to evaluate model quality beyond simple metrics, I want to use LLMs to judge responses with custom criteria, so I can capture nuanced quality dimensions at scale.
The Challenge
Standard benchmarks tell you that GPT-4o scores 87% on MMLU and Claude 3.5 Sonnet scores 88.3%. Useful for general capability assessment, but your RAG pipeline isn’t answering multiple-choice questions about college physics. Your users ask about refund policies, API rate limits, and SSO configuration—and “correctness” has nuances that exact-match scoring can’t capture.
You need evaluation that understands your domain. An answer might be factually correct but miss critical context. Another might be comprehensive but poorly organized. A third might be technically accurate but written at the wrong level for your audience. These distinctions matter for user experience, but traditional scoring methods treat them identically.
Human evaluation captures these nuances, but it doesn’t scale. Hiring contractors to rate 1,000 responses takes weeks and costs thousands of dollars.
How Lattice Helps
LLM-as-Judge uses language models to evaluate other language models, combining the nuance of human judgment with the scale and consistency of automated scoring. You define what “quality” means for your use case through custom scoring prompts and rubrics, and the judge model applies your criteria consistently across thousands of examples.
Scoring Modes
Single Mode: Rate each response independently for absolute quality assessment.
Input: What is our refund policy?Response: You can get a refund within 30 days of purchase...
Judge: Rate this response 1-5 for accuracy and completeness.Reference Mode: Compare responses against ground truth when you have known-correct answers.
Input: What is our refund policy?Response: You can get a refund within 30 days of purchase...Reference: Full refunds are available within 30 days. Enterprise customers have a 90-day window. Contact support@example.com.
Judge: Rate how well the response matches the reference answer.Pairwise Mode: Compare two responses head-to-head for model comparison.
Input: What is our refund policy?Response A (Claude): Full refunds within 30 days...Response B (GPT-4o): You may request a refund...
Judge: Which response is better? A, B, or tie?Scale Types
| Scale | Values | Use Case |
|---|---|---|
| Binary | Pass/Fail | Factual correctness, safety checks |
| Likert-5 | 1-5 | General quality assessment |
| Likert-10 | 1-10 | Fine-grained quality distinctions |
| Continuous | 0.0-1.0 | Precise scoring for aggregation |
All scales are normalized to 0-1 for consistent statistical comparison.
Custom Scoring Prompts
Template variables are replaced with actual values:
{{input}}- The original prompt/question{{output}}- The model’s response{{reference}}- Ground truth answer (reference mode)
Example: RAG Answer Quality
You are evaluating a RAG system's response quality.
User Question: {{input}}System Response: {{output}}Correct Answer: {{reference}}
Evaluate on these dimensions:1. ACCURACY: Is the information factually correct?2. COMPLETENESS: Does it cover all relevant points?3. RELEVANCE: Does it address what was asked?4. CLARITY: Is it well-organized and easy to understand?
Rate 1-5 where:1 = Unacceptable (wrong, incomplete, or confusing)2 = Poor (major issues affecting usefulness)3 = Acceptable (correct but could be better)4 = Good (accurate, complete, well-written)5 = Excellent (exceeds expectations)
Respond with JSON: {"score": N, "reasoning": "..."}Weighted Rubrics
For multi-dimensional evaluation, define criteria with weights:
| Criterion | Weight | Description |
|---|---|---|
| Factual Accuracy | 40% | Information correctness vs reference |
| Completeness | 25% | Covers all relevant points |
| Clarity | 20% | Organization and readability |
| Tone | 15% | Appropriate for audience |
The rubric is included in the judge prompt, guiding evaluation across dimensions. Weighted scoring produces a single aggregate score while preserving dimensional breakdown.
Pairwise Comparison
For direct model comparison, pairwise mode avoids absolute scoring bias:
Compare these two responses to the same question.
Question: {{input}}
Response A:{{response_a}}
Response B:{{response_b}}
Which response better addresses the question?
Respond with JSON: {"winner": "a" | "b" | "tie", "confidence": 0.0-1.0}Pairwise results are aggregated into:
- Win Rates: Percentage of comparisons won by each model
- ELO Ratings: Chess-style ratings from pairwise outcomes
Technical Considerations
Temperature 0.0: Judge responses should be deterministic for reproducibility.
Concurrency Control: Use asyncio semaphores to limit parallel LLM calls and prevent rate limit errors.
Cost-Effective Judging: Using Haiku or a smaller model for judging keeps costs manageable while maintaining evaluation quality.
Score Normalization
All scale types normalize to 0-1 for consistent aggregation:
| Scale | Original | Normalized |
|---|---|---|
| Binary | 0, 1 | 0.0, 1.0 |
| Likert-5 | 1-5 | 0.0, 0.25, 0.5, 0.75, 1.0 |
| Likert-10 | 1-10 | 0.0 to 1.0 |
Statistical Aggregation
For each target, the framework computes:
- Mean: Average normalized score
- Median: Middle value (robust to outliers)
- Standard Deviation: Score variability
- 95% Confidence Interval: Range where true mean likely falls
Real-World Scenarios
A product team measuring answer quality configures LLM-as-Judge with a custom rubric weighting accuracy (40%), completeness (30%), clarity (20%), and tone (10%). They run weekly evaluations against 200 production questions.
An ML engineer comparing embedding models uses pairwise comparison to avoid absolute scoring bias. They run 500 pairwise comparisons and find the new embeddings win 62% of head-to-head comparisons.
A research scientist validating prompt changes creates a reference-mode evaluation with 100 questions and verified answers. The new prompt scores 4.2 average vs 3.9 for the old—a statistically significant improvement.
A platform team establishing quality baselines runs LLM-as-Judge with inter-rater reliability checks. They find their initial scoring prompt has only 65% agreement, indicating ambiguous criteria. After refining, agreement increases to 88%.
What You’ve Accomplished
You now have LLM-as-Judge evaluation configured with:
- Scoring mode matched to your evaluation needs
- Custom prompt capturing domain-specific criteria
- Weighted rubric for multi-dimensional assessment
- Statistical aggregation for reliable results
What’s Next
LLM-as-Judge integrates with the broader Evaluation Framework:
- Evaluation Creation: Configure judge settings during evaluation setup
- Evaluation Runs: Execute evaluations with real-time progress tracking
- Evaluation Comparison: Visualize judge results with charts and statistical significance
LLM-as-Judge is available in Lattice. Evaluate with the nuance of human judgment at the scale of automation.
Ready to Try Lattice?
Get lifetime access to Lattice for confident AI infrastructure decisions.
Get Lattice for $99