Configure Infrastructure.
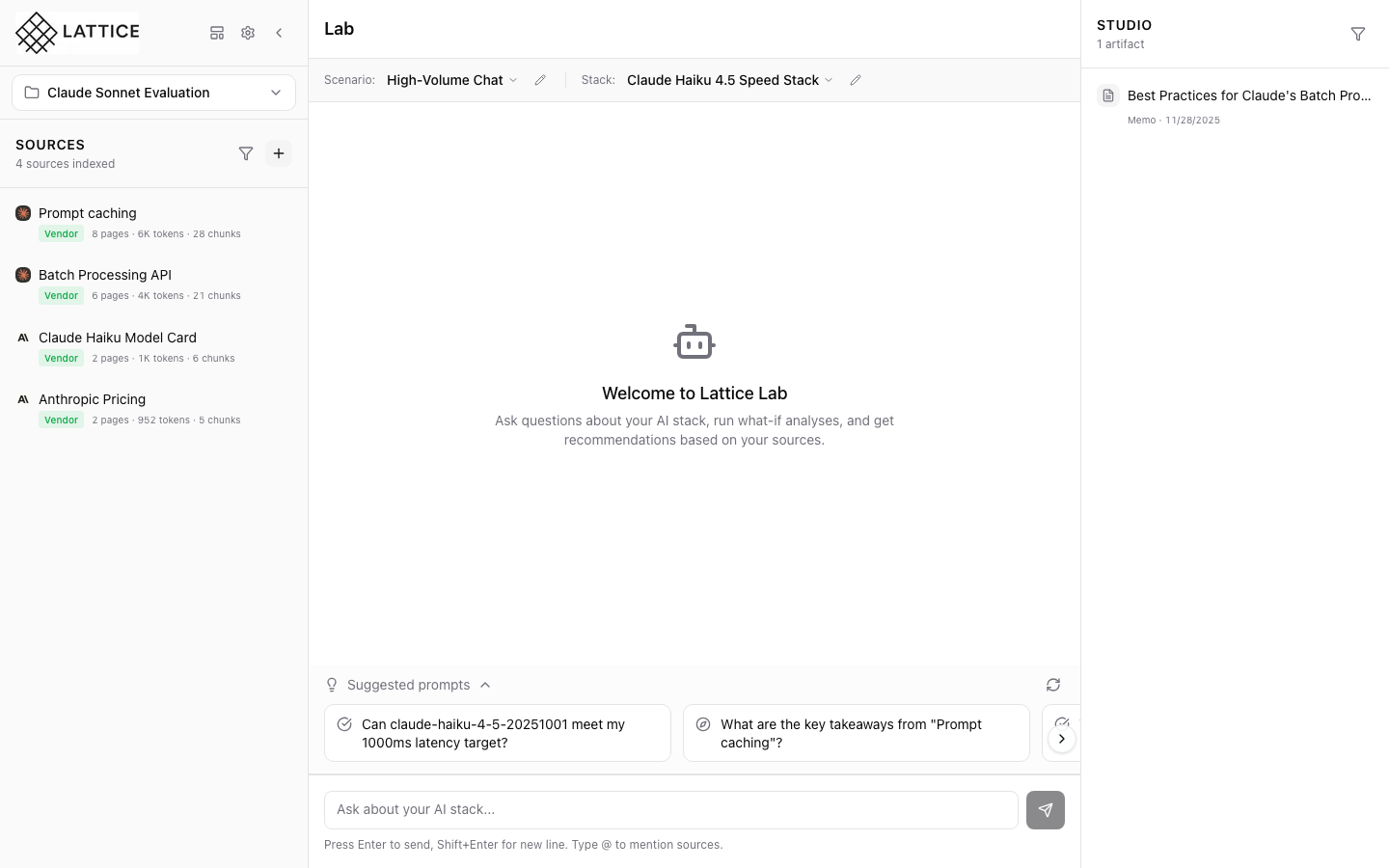
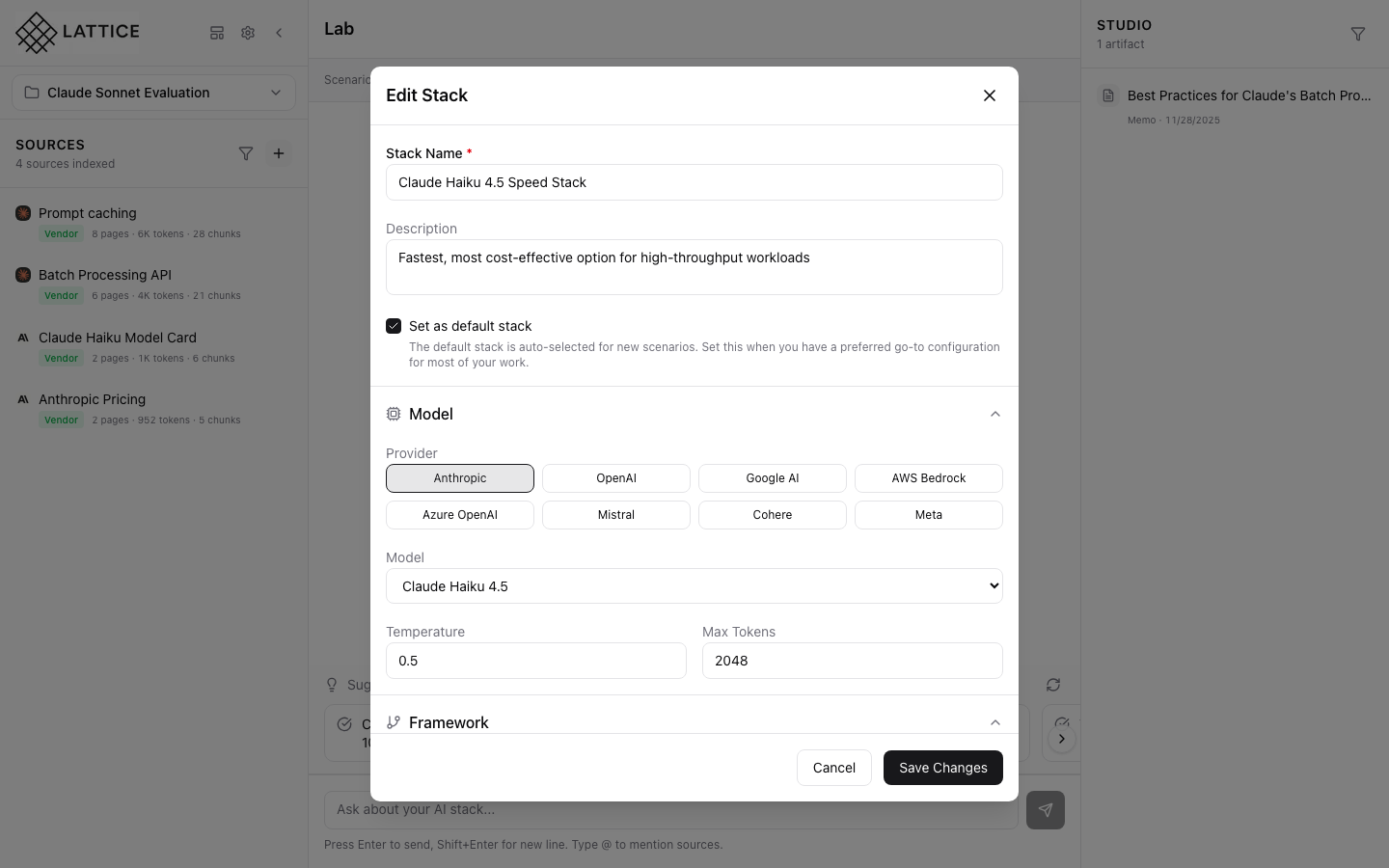
Model Selection
Choose from supported LLM providers and models. Compare capabilities, pricing, and performance characteristics to find the right fit for your use case.
- Anthropic Claude: Haiku, Sonnet, Opus variants
- OpenAI: GPT-4, GPT-4o, o1 reasoning models
- Google Gemini: Pro, Flash, Ultra options
- Meta Llama: 3.3 70B, 3.1 405B for self-hosting
- Mistral AI: Large, 7B edge deployments
- Embedding Models: text-embedding-3, voyage-3
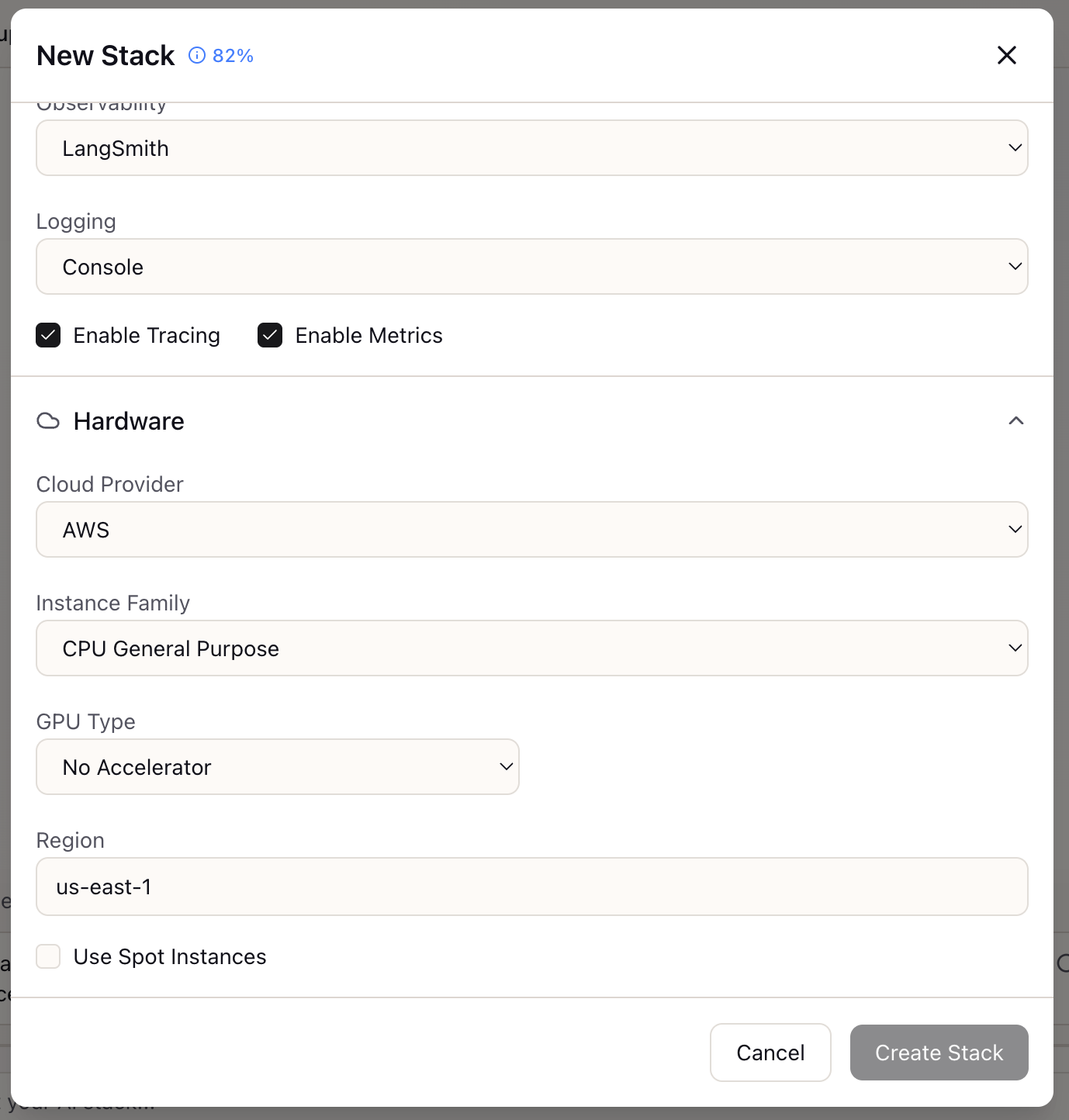
Hardware Configuration
Specify GPU requirements for self-hosted deployments. Lattice helps you understand hardware needs for different models and throughput targets.
- NVIDIA GPUs: A100, H100, L40S options
- Memory Calculator: VRAM requirements per model
- Multi-GPU: Tensor parallelism configurations
- Cloud Providers: AWS, GCP, Azure instances

Framework Selection
Select inference frameworks and serving solutions. From vLLM to TensorRT-LLM, choose the right tools for your deployment requirements.
- vLLM: High-throughput serving with PagedAttention
- TensorRT-LLM: NVIDIA-optimized inference
- Triton Server: Multi-model serving platform
- SGLang: Structured generation optimization
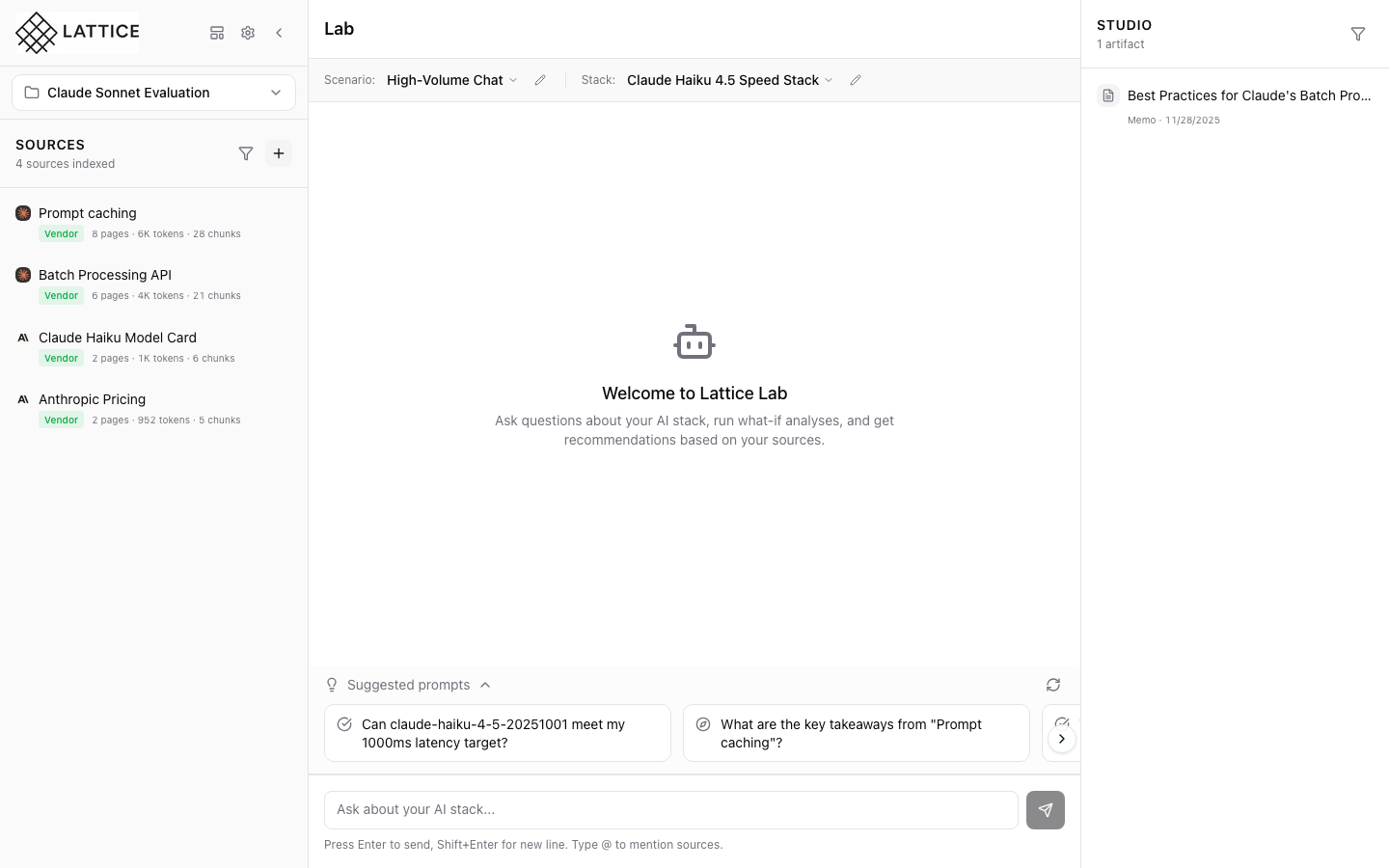
AI-Suggested Stacks
Let Lattice recommend optimal stack configurations based on your scenario. Get suggestions grounded in vendor documentation and real-world benchmarks.
- Scenario-Optimized: Match SLO requirements
- Cost Analysis: Price vs performance tradeoffs
- Benchmark Citations: Vendor performance data
- Comparison View: Side-by-side stack options
Technical Specifications
Everything you need to know about stack configuration options and supported infrastructure in Lattice.
Model Providers
- API Providers - Anthropic, OpenAI, Google, Mistral
- Self-Hosted - Meta Llama, NVIDIA NIM
- Embeddings - OpenAI, Voyage, Cohere
Hardware Options
- GPUs - A100, H100, L40S, RTX 4090
- Memory - 40GB, 80GB, multi-GPU configs
- Platforms - AWS, GCP, Azure, Lambda Labs
Frameworks
- Serving - vLLM, TensorRT-LLM, Triton
- Training - DeepSpeed, FSDP, Megatron
- Optimization - FlashAttention, GPTQ, AWQ
Learn More About Stacks
Explore guides and documentation to configure optimal AI infrastructure.
Journey Guides
Configure Your AI Stack
Get AI-powered stack recommendations optimized for your specific requirements.
Get Lattice for $99